Personal notes while grokking for system design interviews
Notes are based on the content in Alex Xu's book System Design Interview - An Insider's Guide
Some quick-fire notes (CH 1+2)
Relational Database vs Non-relational Database
Non-relational is better if:
- Application requires super-low latency (due to lack of ACID [atomicity, consistency, isolation, durability])
- Data is unstructured (self-explanatory)
- Need to store a massive amount of data (if willing to sacrifice ACID, can achieve higher write speeds & easier horizontal scaling).
Vertical scaling vs horizonal scaling
- TLDR: better specs vs more computing nodes
- Vertical scaling has a hard limit due to exponential cost increase, also lacks failover and redundancy.
Load balancing vs data replication
- Load balancing usually refers to balancing traffic between web-tier servers, for easier horizontal scaling and redundancy.
- Data replication refers more towards replicating data to multiple DB servers. In master/slave model, slave servers only supports read operations. Only the master DB supports write, this usually works because applications usually have a higher ratio of reads to writes.
- Leads to better performance due to horizontal scaling of db reads
- Redundancy & availability is present too because slave DBs can be across multiple physical locations.
- If all slave DBs are down, read operations will be directed to master db, and an admin can replace the slave DB eventually.
- If master DB goes down, one slave DB will be promoted to master.
Caching
- Exists as another layer between DB and web-tier, speed up reads of frequently used data.
Some numbers
| Latency numbers | Time |
|---|---|
| L1 cache ref | 0.5ns |
| Branch mispredict | 5ns |
| L2 cache ref | 57ns |
| Mutex lock/unlock | 100ns |
| Main memory ref | 100ns |
| Compress 1K bytes | 10µs |
| Send 2K bytes over 1Gbps network | 20µs |
| 1MB sequential read from memory | 250µs |
| Round trip within a datacenter | 500µs |
| Disk seek | 10ms |
| 1MB sequential read from network | 10ms |
| 1MB sequential read from disk | 30ms |
| Packet from CA to Netherlands | 150ms |
| Availability % | Downtime/day | Downtime/year |
|---|---|---|
| 99% | 14.40 mins | 3.65 days |
| 99.9% | 1.44 mins | 8.77 hours |
| 99.99% | 8.64 secs | 52.60 mins |
| 99.999% | 0.864 secs | 5.26 mins |
System Design Interview Framework (CH 3)
Section contains content mostly from https://www.hellointerview.com/learn/system-design/in-a-hurry/delivery instead
Time estimate is based on a 40 minute interview slot.
1) Understand problem, establish design scope (est. 5 mins)
At the start, always ask questions. Estabilish functional requirements:
- e.g. For Twitter, user should be able to post tweets, follow other useres, see tweets from users they follow.
- e.g. For designing a cache, Clients should be able to insert items, set expirations, read unexpired items.
- Identify and focus on only the top 3 functional requirements, it's only an interview so there's very little time.
For non-functional requirements, we talk more about the qualities of the system we're designing:
- e.g. System should be highly available, prioritize availability over consistency
- e.g. System should be able to support xxx number of daily active users
- e.g. Service provided by system should be low-latency.
Some guiding points for non-functional requirements:
- CAP Theorem: In a distributed system, there is always Partition Tolerance, so we have to choose between Consistency and Availability.
- Environment constraints: Any constraints on the environment where the system runs? (i.e. design an app for a mobile device with limited battery life).
- Scalability: What is the traffic pattern like, will it peak at a specific time of the day? Consider read vs write ratio as well to scale the system accordingly.
- Latency: How fast does the system need to respond to user requests?
- Durability: How important is it that the data in the system is not lost? Social network system can tolerate some data loss but a banking system cannot.
- Security: How secure the system needs to be?
- Fault tolerance: How well does the system need to handle failures? Consider redundancy, failover and recovery mechanisms.
- Compliance: Are there any legal requirements to meet?
2) Define core entities (est. 2 mins)
e.g. For designing Twitter, there are Users, Tweets and Follows.
3) Define API/System Interfaces (est. 5 mins)
For most web applications, stick to using REST for simplicity. Establish the REST endpoints in this step.
4) High level design (est. 10 mins)
Come up with the initial blueprint, draw boxes and arrows to represent different components and how they interact with one another.
- Ask for feedback after coming up with an initial blueprint, talk to the interview to get him involved as well to design the system together.
- Write rough estimated numbers in the diagram to see whether blueprint fits scale constraints, though ask the inteviewer whether this is necessary beforehand.
- Typically involves an API gateway after clients which fans out to other services, each service having their own cache and possibly own DB as well.
- May not be efficient, get some ideas about areas to focus on in the next step based on interviewer's feedback.
Example of a high-level design blueprint for Twitter:
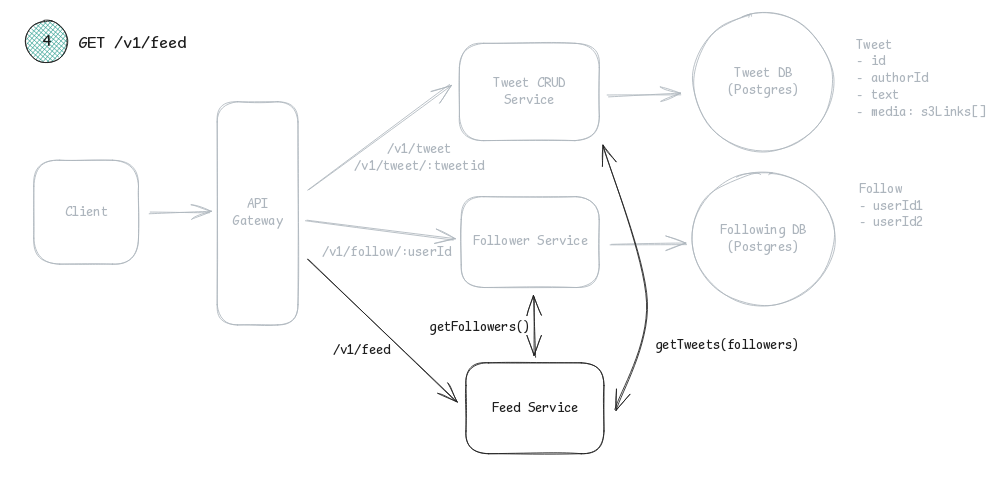
5) Deep dive (est. 15 mins)
Dive into details of some system components. This can differ from system to system.
- e.g. for URL shorterner, how to design a hash function that converts a long URL into a short one.
- e.g. for chat system, how to minimize latency and support online/offline status.
- e.g. for news feed, how to minimize latency of news feed retrieval and publishing.
6) Wrap up (est. 3 mins)
Interviewer may ask follow-up questions or let the interviewee discuss additional points.
- Never say system is perfect, there will always be bottlenecks. It's good to identify them at this stage.
- Give a recap of the design if needed.
- Talk about operation issues, how to monitor metrics and error logs?
- Possibly discuss about scaling as well, e.g. what changes to make if we need to support 10x users?
URL Shorterner (CH 8)
This was the topic that made me failed one of my interviews before, so it was studied earlier.
Establish design scope & define API endpoints
For establishing design scope, ask the following questions:
- Traffic volume (how many URLs generated a day, how many accesses a day?)
- How short a URL must be?
- Allowed characters in the shortened URL
- Whether a shortened URL can be deleted or updated by a user (for the following notes below, assume no.)
Establish REST-ful API endpoints:
- POST api/v1/shorten
- longUrl: longURLString
- returns shortURL
- GET api/v1/shortURL
- returns longURL for HTTP redirection
HTTP 301 vs 302 for redirection
- 301 signifies permanent redirect, browser will cache the response and use it for subsequent requests to the same URL.
- Good for reducing server load.
- 302 signifies temporary redirect, subsequent requests for the same short URL will still be sent to the URL shortening service.
- Good for telemetry and analytics.
High-level idea of URL shortening protocol
- Assume short URL looks like
www.my-domain.com/{hashValue}where we find a hash function to map a long URL to hashValue. Detailed design for the hash function should be discussed in deep dive.
Design Deep Dive
Data model
Best way to store entries for shortened URL would be id(PK), shortURL (varchar), longURL (varchar), good to re-iterate how long of shortURL and longURL we should be supporting.
Hash function
Used to create new shortURL string from a longURL. If only alpha-numerics are allowed, then we have 62 possible characters. Let n be the number of characters in the hash value, it means we will have 62^n number of possible URLs. Choose n based on the maximum number of URLs that will be stored in the system.
Hash function + Collision resolution
If generating shortURL from a truncated value generated from a hash function (e.g. SHA-1), collisions may happen. To resolve it, check whether the generated shortURL exists in DB, and if so, resolve it by salting the input and re-applying the hash function again.
- The salt can be just a global value that increases every time it is used, so that collision chances can be minimized further since the salt value will be unique whenever a URL is salted due to collisions.
- To speed up collision checking, a bloom filter can be used to determine whether a generated shortURL is possibly already in the database.
Base62 encoding
Deterministic and possible reversible compared to using hash functions, and requires a unique ID generation.
- Size of the output is not fixed as it scales with the length of the ID input.
- If we use an increasing PK as ID, collision is impossible but it is easy to figure out the next available ID, which can be a security concern.
- Personal thoughts: why would anyone use this? Why is this even mentioned in the textbook?
Key generation system from Grokking the System Design Interview
Have a standalone key generation service that generates random n letter strings and store it in a database.
kkeys are pre-generated and cached in an "unused key" DB table, so the latency of a URL shortening request is minimized.- When a cached key is used, it should be marked in the database as used already.
- Some keys can even be cached into memory and moved into the "used key" DB table, which is the optimal design for a multi-server key generation system.
- In the case a server dies with some unused keys cached in memory, we lose some unused keys that are already pushed to the "used key" DB table, but this is acceptable due to the large key size.
- In return, we get higher key generation throughput and redundancy.
- To prevent giving same keys to the different web-tier VMs, a lock-free queue must be used.
Data Partitioning and Replication from Grokking the System Design Interview
Easiest way to do so is partition based on first character of the shortURL (i.e. store short url entries in 62 different DB instances).
- Limited horizontal scalability & possibility of having a few overloaded servers
Another way is to do hash-based partitioning, which could provide a more consistent among servers (assuming consistent hashing) and allows for better horizontal scalability.
Caching reads from Grokking the System Design Interview
Assume 80-20 rule where 20% of the URL generates 80% of the traffic, we want to cache these 20% daily most-used short URLs. If we have 20k requests per second, we will get 1.7 billion requests. Assuming 500 bytes of data is loaded for each request, 20% of the 1.7 daily billion requests means ~170GB is required for caching.
- A modern day server with 256GB RAM has more than sufficient amount of memory for caching the system.
- Alternatively, we can use multi-servers with lesser RAM as well, using a similar partitioning technique as mentioned above.
LRU eviction policy should be adopted because it is most reasonable for URL shorterning service.
To further increase redundancy and efficiency, multiple cache servers can be replicated. On cache miss, a cache server would send a request to the database, which will simply push the new entry to all the cache replicas.
DB Cleanup from Grokking the System Design Interview
If one of the requirements involves cleaning of old short URLs, or allowing user to set an expiration date on the short URL, the data schema should be update to allow for lazy clean-up.
- New attributes can be added for the main DB table to track expiration date and whether the entry is deleted by a user.
- Deletion of an entry involves setting the specific entry to have the deleted attribute.
- A periodic clean up service can be introduced remove expired links and user-deleted links that is scheduled to run during low-load periods.
- Clean-up service should also put the key the "unused key" DB table for future key generation usage again.
Rate limiter (CH 4)
Establish design scope & define API endpoints
For establishing design scope:
- Client-side or server-side API rate limiter?
- Throttle API requests based on IP, user ID or other properties?
- Scale of the system?
- Should it work in a distributed environment?
- Design as a separate service or in application code?
- Should be inform users who are throttled?
For non-functional requirements, a rate limiter should have minimal latency and high fault tolerance (such that it does not affect the entire system if it goes down).
High-level design
Rate limiter can exist as both client-side or server-side. We always do server-side rate limitation because client-side rate limits can easily be forged by malicious actors.
Simpliest rate limiter implementation is a middleware/service that exists between load balancer and the client.
Algorithms for rate limiting
Token bucket algorithm: Every client has a "bucket" of tokens, and any request that a client makes costs 1 token, and a number of tokens are refreshed every minute. Take note it's not necessary the case that bucket size == token refill rate.
- Usually different buckets for different API endpoints
- We can deploy a global bucket if a system requires a request limit.
Leaking bucket algorithm: Similar to token bucket, except there exist a FIFO queue between bucket and actual API endpoint, which is dequeued at a fixed rate.
- Burst traffic can fill up the queue with old requests, and cause recent requests to be rate-limited.
Fixed window counter algorithm: Dumbed-down token bucket algorithm, bucket size == token refill rate.
- Memory efficient, but could cause spikes in traffic between bucket refills, causing more requests than allowed quota to go through.
Sliding window log algorithm: Improved version of fixed window counter algorithm, All requests have timestamps logged down. Outdated timestamps outside of the defined sliding window are removed on new requests, reject the new request if number of timestamps logged down in the sliding window reached limit.
- Very accurate rate limiting, but consumes a lot of memory because timestamps of every request have to be stored in memory.
Sliding window counter algorithm: Hybrid of the previous 2, only looks at the timestamp of the new request (as opposed to logging down and looking at timestamps of all the previous packets). Uses fixed window counter algorithm as the base, but calculates whether to let new request pass with this formula: requests in current fixed window + requests in previous window * overlap % of pevious fixed window and current *sliding* window
- More smooth than fixed window algorithm while retaining memory efficiency, but rate limitation may not be as accurate due to the assumption that requests in previous window are evenly distributed. Cloudflare's experiments show 0.003% requests were wrongly rate limited.
Architecture
Use in-memory cache as we want to minimize latency. Redis is good because it supports increments + expiry of keys.
Rate limiter exists as a middleware between client and load balancer/API server. When receiving a new request, middleware fetches the counter from the corresponding bucket in Redis, checks whether limit is reached, and rejects or forwards the request to API servers accordingly. If a request is accepted, the middleware server will increment the counter and save it back to Redis.
Design Deep Dive
Rate limiting rules
There can be different rules set for different components in the system.
Exceeding the rate limit
Rate-limited requests are responded with HTTP 429, but in certain causes we might want to queue the requests instead. Ask the interviewer for specific design choices.
We can use rate limit headers to also tell the client how throttled they are. e.g. headers: X-Ratelimit-Remaining, X-Ratelimit-Limit, X-Ratelimit-Retry-After.
Performance optimization
- Have multiple rate limiter servers set-up as edge servers across the globe, so that requests can be routed to the closest rate limiter to reduce latency
- Gather analytics on how much requests are accepted or dropped due to rate limiting, to check whether the algorithm and rules are effective.